从单幅影像到三维文物重建——方法、边界与应用再认识
近期,我们在《Applied Sciences-Basel》发表了论文《From 2D to 3D: A Generative Model from Single Image to Digital 3D of Chinese Three Gorges Cultural Relics》。这项研究围绕“单张图像生成三维文物”这一问题,提出了一条相对完整的技术路径:以ViT结合DINO提取图像特征,预测Triplane三平面表示,再通过NeRF完成密度与颜色解码,并结合相机参数估计,实现无标定条件下的新视角渲染与网格提取。基于3302件文物图像数据的实验结果表明,这一方法在几何一致性、表面完整性和计算效率等方面,相较多种基线方法具有一定优势。

如果只剩下一张档案照片,文物还能不能“动起来”?这是这项研究最初的问题。论文发表之后,我们更希望把这项方法背后的取舍、适用边界和实际意义讲清楚。它可以作为展示和研究的起点,帮助我们快速获得一种可用的三维表达,但并不能替代高精度扫描,也不能等同于严格意义上的“文物复原”。
单视角条件下的三维问题
在常规三维建模中,我们通常依赖多视角摄影测量或三维激光扫描等手段。这类方法需要从不同角度获取连续影像,或借助专门设备采集高精度几何信息。例如,对遗址或建筑进行环绕拍摄,才能拼接出完整的三维模型。但在实际工作中,这样的条件并不总是具备。
对于大量文物档案而言,往往仅留存有一张二维照片,而且还存在当时拍摄条件有限、光照不足、遮挡明显、角度单一等问题。
从计算机视觉的角度看,由二维恢复三维,本质上是一个典型的不适定问题。单一视角并不能唯一对应一个三维结构,理论上可以存在多种解释。比如一件器物的侧面照片,其背面形态、底部结构乃至部分细节,在图像中都没有直接信息,只能依赖推断。
人眼在这方面反而更有优势。我们可以凭经验判断器型,依据纹饰推测风格,甚至下意识地补全对称结构或联想相似器物。但对计算机来说,这种“经验”并不存在,只能通过数据训练和模型设计去逼近。因此,这项工作的出发点并不是替代传统精确采集,而是为信息不足的场景提供一种可行路径。
原因很简单。单视角天然缺少深度、尺度以及背面和遮挡区域的信息,同时也缺乏多视角之间的几何约束。面对同一张图像,往往可以得到多种“看起来合理”的三维结果,而这些结果并不一定唯一,也不一定真实。
因此,我们更倾向于把这项任务理解为一种“推测式的三维表达”。在技术上,它对应的是学习一个从二维图像到三维隐式表示的映射:输入一张RGB图像,预测一个连续的三维场,再进一步提取为可交互的网格模型。
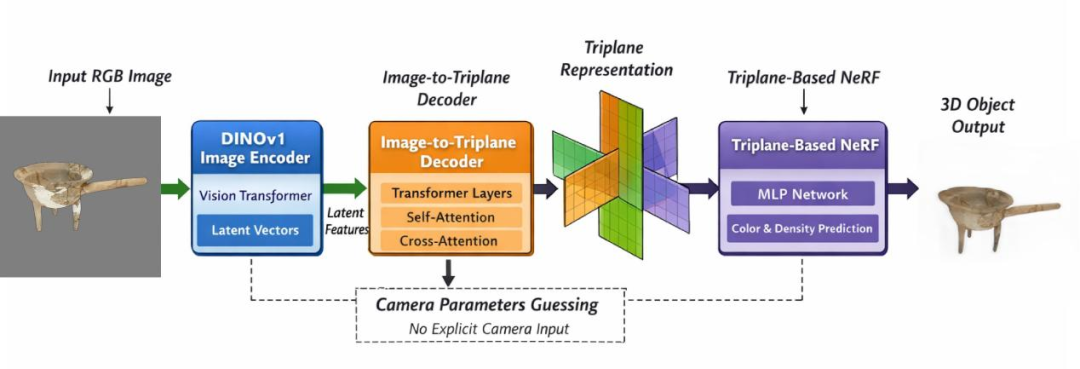
论文所提方法的整体框架
这里的关键,不在于是否“精确还原”,而在于是否“可用”。具体来说,至少要满足三个方面:一是结构连贯,模型在不同视角下应保持基本一致,不出现明显的前后矛盾;二是器型可信,整体比例与形态应符合基本认知,尽量接近类型学经验,而不是任意生成;三是效率可控,能够支持批量处理,而不是每件文物都需要长时间人工干预或复杂优化。
把这些边界说清楚,并不是降低目标,而是为了让这项技术在实际工作中被合理使用。与其将其描述为“复原手段”,不如更准确地理解为一种补充工具——在缺乏完整数据的情况下,提供一个可以使用的三维表达。
从图像到三维的实现路径
为了便于理解这项工作,可以把整个过程看作一条从图像走向三维的处理路径。但与其说是“模型流程”,不如说是对几个现实问题的逐步回应。
首先,是信息不足。单张图像没有深度信息,我们只能依赖模型学习到的经验,去补全那些本就不可见的部分。其次,是表达成本。如果三维表示本身过于复杂或计算代价过高,就很难在应用上推广。再一个,是实际条件的限制。很多图像缺乏相机参数,背景也不干净,模型必须能够在这种非理想环境下稳定工作。
围绕这些约束,单图三维重建大致形成了两条技术路径:一类是先“补数据”,通过扩散模型生成伪多视角,再进行融合;另一类是直接学习一个可渲染的三维表示,让模型在内部完成多视角一致性的构建。
现有一些工作分别沿着这两条路径推进:有的侧重多视角生成的效率优化,有的引入扩散模型提升重建质量,也有研究证明可以通过Transformer直接预测Triplane结构,并进一步解码为NeRF表示。相比之下,我们更倾向于后者——让模型直接生成一个可渲染的三维场,并在统一的相机轨迹下进行验证,从而尽量避免“正面成立、侧面失真”的问题。
如果换一种更直观的说法,这个过程大致可以理解为:先把图像看明白,再把信息压缩成一种便于计算的结构,接着恢复为连续的三维表达,最后在不同视角下进行校验和调整。
关键技术的基本思路
从技术发展脉络来看,这项工作并不是突然出现的。早期的Occupancy Networks和DeepSDF,已经尝试用连续函数表达三维几何,从而摆脱对分辨率的依赖;而NeRF进一步把几何与外观统一进隐式表示,通过立体渲染生成新视角,逐渐成为这一方向的重要基础。
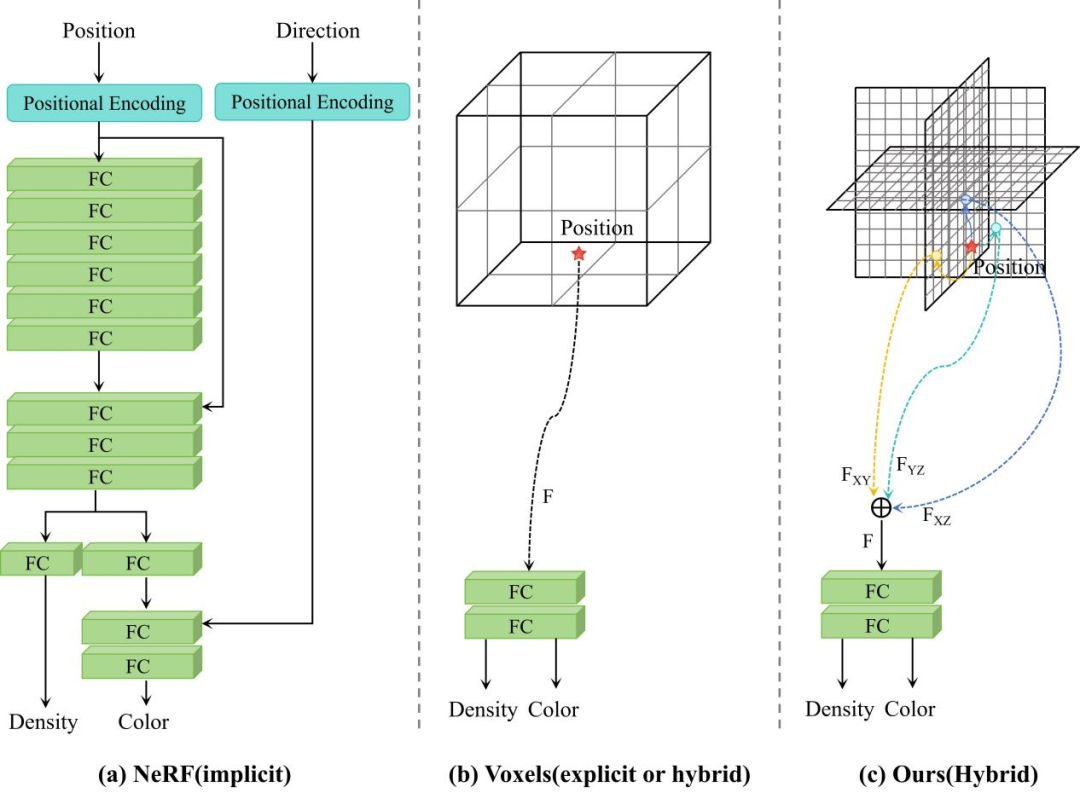
三种神经场景表示方法(a)隐式表示(b)显式表示(c)混合表示
我们在文物场景中沿用了这条技术路线,但关注点有所不同:不是单纯追求重建精度,而是要让方法在“单张图像、无相机参数、图像质量不稳定”的条件下依然能够工作。
首先是对图像的理解能力。相比传统卷积网络更多依赖局部纹理,视觉Transformer更擅长处理整体结构关系,例如器物各部分之间的比例、轮廓的对称性,以及纹饰在空间中的分布。这类信息对于三维推断非常关键。因此,我们采用ViT作为编码器,并通过注意力机制将图像语义逐步引入三维表示。
在此基础上,引入DINO自监督预训练,是为了让模型在没有标注的情况下形成更强的结构感知。这类特征往往会自然呈现出类似分区的效果,把器物划分为相对稳定的部件区域。在实际实验中可以看到,当缺少相关形制与结构经验约束时,模型在遮挡区域的补全会变得不稳定,整体重建精度也会下降。这一点对单图任务尤为关键。
接下来是三维表示本身。我们没有直接使用体素或纯隐式函数,而是采用了Triplane这种折中的表达方式。可以简单理解为:用三张正交的二维平面来承载三维信息,通过投影和插值恢复空间特征。这样既避免了体素在高分辨率下的内存问题,也降低了隐式函数逐点计算的开销。在我们的任务中,这种表示方式的意义不仅在于效率,更在于它具备实际部署的可行性,使单张图像的三维推理能够在较短时间内完成。
在获得空间特征之后,还需要把这些特征转化为可以“看见”的结果。这里使用的是类似NeRF的隐式体积表示:通过一个轻量网络,将空间位置映射为密度和颜色,再通过立体渲染生成不同视角下的图像。这一过程既可以用来检查多视角的一致性,也可以进一步提取出显式网格模型,满足展示或分析需求。
最后一个关键环节,是相机参数的估计。与标准NeRF不同,档案照片通常缺乏标定信息,如果直接使用固定相机模型,很容易导致几何结构失真。因此,我们增加了一个轻量的预测分支,从图像整体特征中估计相机的焦距和位姿,并与重建过程共同优化,使模型在无标定条件下也能够完成基本的三维重建与渲染。
实验设计与评价方式
实验使用了3302件文物图像数据,涵盖陶器、瓷器、青铜器、玉器及石刻等多种类型。数据按2500件训练、500件验证、302件测试进行划分,以保证模型训练与独立评估之间的基本平衡。

实验结果可视化展示
需要说明的是,相当一部分文物并没有对应的实测三维扫描数据。因此,本研究采用由专业人员依据资料复原并经核验后的三维模型作为参考值。这类数据并不等同于高精度实测结果,但在当前条件下,可以提供一个相对稳定且具有专业依据的参照体系,用于模型训练与方法对比。
在评价方式上,我们选择了三类互补指标,分别对应几何一致性、表面完整性以及计算效率。几何精度采用Chamfer Distance,用于衡量模型表面之间的整体偏差;表面完整性通过不同阈值下的F-score进行评估,更侧重反映重建结果在细节层面的覆盖与匹配情况;同时记录推理时间,以评估方法在实际应用中的可行性。
此外,为了将隐式三维表示转化为可直观展示的结果,我们使用Marching Cubes算法提取等值面,并在需要时生成纹理贴图,以便于后续展示与分析。
结果表现与实际案例
从定量结果来看,这一方法在测试集上的整体表现优于多种代表性方法,如One-2-3-45、ZeroShape、TGS、LRM、VGGT等,并通过统计检验达到显著性水平。具体而言,Chamfer Distance距离降至0.163,相较表现较好的基线方法VGGT(0.170)约有4.1%的提升;F-score在不同阈值下分别达到0.622、0.756和0.848,均为同类方法中的较优结果。
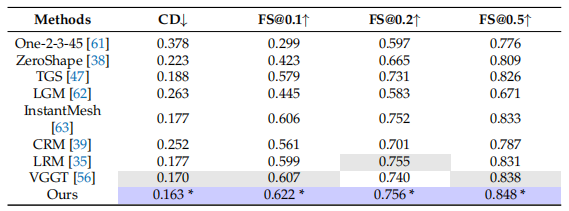
不同方法在测试集上的定量对比

与LRM方法的定性对比
这些指标更重要的意义,在于它们反映了模型的可用性。一方面,整体几何形态更接近参考模型;另一方面,表面缺失与碎裂情况有所减少,尤其在更严格的评估阈值下仍能保持优势,说明细节层面的稳定性有所提升。在效率方面,单张图像从三维表示生成到网格提取的完整推理过程,大致控制在1.5至2.0秒之间,峰值显存约6.4GB。在单卡环境下,处理约1000件文物图像的总耗时约为35分钟。相比之下,依赖逐模型优化的传统方法,往往需要对单件数据进行数十分钟级的迭代,这在大规模场景中很难真正应用。
如果不看指标,从更直观的角度来看,一个关键判断标准其实很简单:模型在旋转之后,是否仍然像同一件器物。实验中的多视角对比显示,在统一采样的不同视角下,模型能够较好地保持尺寸比例、轮廓连贯性以及轴对称特征,即便是输入图像未覆盖的区域,也能维持基本稳定;而部分基线方法在未见视角下更容易出现厚度突变、局部破碎或结构退化。
在具体应用层面,可以通过两个更贴近实际场景的例子来理解这类方法的价值与边界。
对于陶器和瓷器这类器型相对明确的器物,单张图像往往已经包含较充分的轮廓信息。在这种情况下,生成的三维模型可以较好地恢复口沿、腹部弧度及底足收分等关键结构。在展示系统中,将其转化为可旋转的交互模型后,观众能够从不同角度理解比例关系和整体体量,这种空间直观性是二维图像难以提供的。
而在青铜器或玉器等材质更复杂的对象上,不确定性会明显增加。论文中也呈现了一些不稳定或失败的情况:例如高反光或半透明材质会削弱图像中的有效线索,使几何推断出现多解;部分模型可能出现纹饰缺失、厚度塌陷或局部形变。这类结果更适合用于展示或初步讨论,而不应直接作为复原依据。
最后,还有一点在方法层面同样重要。通过消融实验可以看到,不同模块的作用是明确的:缺少相机估计会导致整体结构明显失稳,去掉DINO预训练会直接影响几何精度,而三平面分辨率则需要在细节表达与计算效率之间取得平衡。这说明整个方法并非简单叠加模块,而是在不同环节上分别回应了现实问题中的关键约束。
局限与使用边界
生成式三维的意义,在于让更多原本无法进入三维体系的文物具备一种可用的空间表达。但需要明确的是,它并不能替代“文物复原”,也不应被等同看待。
从实践来看,这类方法的局限主要来自几个方面。
首先是信息本身的缺失。图像中未出现的结构,无论是背面形态还是被遮挡的部分,本质上都只能依赖模型的经验进行推测,而不是基于直接观测。其次是多解性问题。同一张图像,往往可以对应多种合理的三维解释,算法只能给出其中一个相对“更可能”的结果,但并不具备唯一性。
另外,模型对数据分布较为敏感。当输入图像的风格、质量或拍摄条件偏离训练数据时,更容易出现伪影或结构不稳定的情况。档案照片中常见的退化、复杂背景等因素,会进一步放大这一问题。再就是材质层面的限制。当前方法主要聚焦于几何结构与颜色信息的分析,但在高光、透明或复杂反射等场景下缺乏有效的建模手段,因此在处理这类对象时表现会明显不稳定。
基于这些特点,在实际应用中,我们更倾向于遵循一些基本原则:将结果明确标注为“推测生成”,避免与实测或复原混用;关键研究判断仍然建立在可验证的证据之上;对不确定区域进行适当提示;对于重要对象,仍需结合扫描或摄影测量,并通过专家校正形成闭环。只有在这样的前提下,这类方法才不会引入新的误读,而是成为现有技术体系的补充。
结语
回到最初的问题:如果只剩下一张照片,文物能不能“动起来”?从目前的结果看,在一定边界内,我们已经可以得到结构基本自洽的三维表达,并且具备较高的计算效率,能够支撑档案规模的应用。
但比“能不能做到”更重要的,是如何理解这项技术的作用。当数据条件有限时,它可以帮助启动展示或提供初步分析的依据;而在条件充分的情况下,基于测量的三维采集,仍然是高精度记录的基础。
有几个方向值得持续推进:一是与实测数据的结合——用生成方法快速补全,用测量数据进行关键校正;二是把文物领域知识引入模型或流程,让类型学和工艺技术参与约束,而不是完全依赖数据驱动;三是对不确定性的表达,让模型不仅给出结果,也能提示其可靠性范围。
后续希望在可复现的基础上,与更多研究者一起讨论更适合文物场景的训练方式和表达方法。
